Valid Test DP-750 Test, DP-750 Pass4sure Dumps Pdf
Wiki Article
In this society, only by continuous learning and progress can we get what we really want. It is crucial to keep yourself survive in the competitive tide. Many people want to get a DP-750 certification, but they worry about their ability. Using our products does not take you too much time but you can get a very high rate of return. Our DP-750 Quiz guide is of high quality, which mainly reflected in the passing rate. We can promise higher qualification rates for our DP-750 exam question than materials of other institutions.
The Channel Partner Program Implementing Data Engineering Solutions Using Azure Databricks DP-750 certification enables you to move ahead in your career later. With the Microsoft DP-750 certification exam you can climb up the corporate ladder faster and achieve your professional career objectives. Do you plan to enroll in the Implementing Data Engineering Solutions Using Azure Databricks DP-750 Certification Exam? Looking for a simple and quick way to crack the Microsoft DP-750 test?
Get Actual and Authentic Microsoft DP-750 Exam Questions
Unlike many other learning materials, our Implementing Data Engineering Solutions Using Azure Databricks guide torrent is specially designed to help people pass the exam in a more productive and time-saving way. On the other hand, DP-750 exam study materials are aimed to help users make best use of their sporadic time by adopting flexible and safe study access. People always tend to neglect the great power of accumulation, thus the DP-750 Certification guide can not only benefit one's learning process but also help people develop a good habit of preventing delays. Our DP-750 exam questions will help you obtain the certification.
Microsoft Implementing Data Engineering Solutions Using Azure Databricks Sample Questions (Q72-Q77):
NEW QUESTION # 72
You have an Azure Databricks workspace that is enabled for Unity Catalog and contains a catalog named CatalogV Catalog1 contains a schema named Schema! and a table named Table1.
You need to ensure that access to the data in Table1 is controlled by using attribute based access control (ABAC).
What should you apply to Table1, and how should you control access for users? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: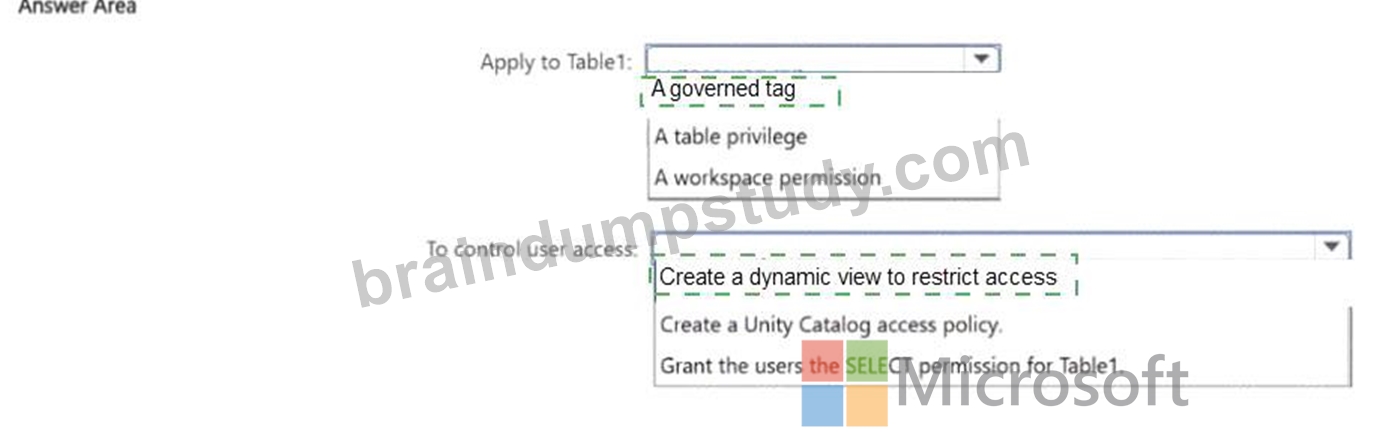
Explanation:
Attribute-based access control (ABAC) in Unity Catalog is implemented through row filters. A row filter is a SQL function registered on a table that evaluates the identity or group membership of the querying user and returns only the rows they're entitled to see.
The key functions are CURRENT_USER() (returns the logged-in user's email) and IS_ACCOUNT_GROUP_MEMBER() (returns true if the user belongs to a specified group). By building filter logic around these, you create access rules that are data-driven - a user in the 'EMEA' group sees EMEA rows, a user in 'APAC' sees APAC rows - without maintaining separate table-level grants per data segment.
This is what distinguishes ABAC from role-based access control: decisions are based on the user's attributes evaluated at query time, not on static grant lists. The filter is transparent to end users - they query the table normally and only receive rows the policy allows.
Reference: https://learn.microsoft.com/en-us/azure/databricks/data-governance/unity-catalog/row-and-column- filters
NEW QUESTION # 73
Case Study 1 - Contoso, Inc.
Overview
Company Information
Contoso, Inc. is a renewable energy provider that operates solar and wind farms across North America.
Existing Environment
Azure Environment
Contoso has a single Azure Databricks workspace named Workspace1 in the West US Azure region. Workspace1 is enabled for Unity Catalog.
Workspace1 contains all-purpose clusters for both development and production workloads.
The company's Azure environment contains:
- In the West US, Central US, and East US Azure regions, Azure event hubs that stream telemetry data and an Azure Data Lake Storage Gen2 account in each region for each hub
- A single Azure SQL database in the West US region that hosts enterprise resource planning (ERP) data
- An Azure Database for PostgreSQL server in the West US region that stores operational maintenance data Data Environment Contoso ingests the following operational and business data:
- Telemetry data: More than 40,000 IoT sensors across 28 sites emit JSON telemetry events every few seconds. Each site sends the events to the nearest event hub, which writes the data into the corresponding Data Lake Storage Gen2 account. These files frequently experience schema drift.
- Maintenance logs: Maintenance systems generate historical repair logs, daily incremental updates, technician notes, and unstructured attachments that are stored in the Data Lake Storage Gen2 accounts.
- Operational maintenance data: Structured operational maintenance data is stored on the Azure Database for PostgreSQL server.
- External weather data: Hourly weather forecasts are retrieved from a REST API and written to the Data Lake Storage Gen2 accounts.
- ERP data: Daily CSV extracts of 50 to 100 GB contain equipment metadata, work orders, and purchase order information.
Problem Statements
The company's existing analytics environment has several issues:
Ingestion
- Telemetry pipelines fall behind during peak loads.
- Telemetry ingestion fails when schema drift occurs.
- Streaming pipelines reprocess events after a pipeline restarts.
Compute
Production and development workloads run on the same all-purpose clusters.
Production and development workloads do NOT support autoscaling or workload isolation.
Governance
- The ERP data is duplicated across systems and development teams.
- Naming conventions are inconsistent across development teams, regions, and products.
- Ownership of the IoT sensors changes over time, and analysts must track the full history of the ownership.
- Occasionally, equipment manufacturers must correct data-entry mistakes in equipment names.
Historical values are NOT required.
Pipeline operations
- Pipelines lack resiliency, alerting, and centralized scheduling.
Requirements
Planned Changes
Contoso plans to implement the following changes:
- Implement scalable data pipeline orchestration.
- Create a managed analytics catalog in Unity Catalog.
- Implement a consistent approach to creating curated datasets.
- Establish a centralized governance model across ingestion, cleansed, and curated layers.
- Grant data engineers access to the ERP tables by using minimal development effort.
- Adopt a compute strategy that isolates production workloads and supports autoscaling.
- Adopt a slowly changing dimension (SCD) approach to address current data modeling issues.
Technical Requirements
Contoso identifies the following environment and compute requirements:
- Ensure that production ingestion workloads run on compute clusters that can scale automatically during telemetry spikes.
- Provide fast and consistent performance for business intelligence (BI) workloads.
- Prevent development activity from affecting production pipelines.
- Production ingestion workloads must run as scheduled, non-interactive pipelines rather than on shared interactive development clusters.
Contoso identifies the following data ingestion and processing requirements:
- Auto-scale ingestion pipelines to handle bursty workloads.
- Handle schema drift for the maintenance and telemetry data.
- Ingest file-based telemetry data by using minimal operational effort.
- Store all the ingested data in a format that supports incremental processing.
- Support the continuous ingestion of telemetry data from the event hubs by using exactly-once semantics.
- Support the ingestion of the structured maintenance data from the Azure Database for PostgreSQL server.
- Build a new telemetry pipeline that ingests raw events from the event hubs, cleanses the data, and publishes curated tables to Unity Catalog.
- Ensure that the Apache Spark Structured Streaming pipelines reading from the event hubs write the data into a managed Delta table named telemetry.raw_events. The pipelines must support schema drift and resume processing after failures without reprocessing the data.
Contoso identifies the following data modeling and optimization requirements:
- Build curated tables that standardize business logic.
- Overwrite equipment metadata attributes, such as name, manufacturer, model, and commissioning date, when the attributes change. Historical values are NOT required.
Contoso identifies the following pipeline deployment and operation requirements:
- Orchestrate multi-step ingestion and transformation workflows.
- Define a clear execution order and dependencies.
- Automatically retry failed steps and notify operators.
- Schedule ingestion and transformation workloads consistently.
Governance Requirements
Contoso identifies the following governance requirements:
- Centralize the metadata catalog.
- Provide isolated development areas that follow standard naming conventions.
- Establish a consistent structure for organizing raw, cleansed, and curated data.
- Provide a read-only mechanism to reference the ERP data through a foreign catalog.
Business Requirements
Contoso identifies the following business requirements:
- Improve ingestion reliability and reduce operational effort.
- Standardize data definitions across development teams.
You need to configure compute for the ingestion of telemetry data. The solution must meet the data ingestion and processing requirements. What should you do?
- A. Enable Photon acceleration for a job compute cluster.
- B. Move the ingestion pipelines to shared compute.
- C. Disable autoscaling for a job compute cluster.
- D. Increase an all-purpose cluster to a larger fixed node type.
Answer: A
Explanation:
Enabling Photon acceleration on a job compute cluster is the best option. It significantly speeds up data engineering pipelines, handles JSON file ingestion seamlessly, and optimizes cost- efficiency for bursty production workloads, which are key for processing rapidly arriving IoT sensor events.
Enable Photon acceleration for a job compute cluster:
Databricks Auto Loader is designed for low-latency, high-volume file ingestion. Running Auto Loader on a job compute cluster provides the lowest operational cost because job clusters are billed at a much lower rate than all-purpose clusters.
Enabling Photon acceleration heavily optimizes the ingestion, parsing, and processing of raw JSON data strings, allowing the cluster to handle bursty workloads faster and auto-scale more efficiently.
Scenario, Data Environment, Contoso ingests the following operational and business data:
Telemetry data: More than 40,000 IoT sensors across 28 sites emit JSON telemetry events every few seconds. Each site sends the events to the nearest event hub, which writes the data into the corresponding Data Lake Storage Gen2 account. These files frequently experience schema drift.
Contoso identifies the following data ingestion and processing requirements:
-> Auto-scale ingestion pipelines to handle bursty workloads.
Handle schema drift for the maintenance and telemetry data.
-> Ingest file-based telemetry data by using minimal operational effort.
Reference:
https://medium.com/@krthiak/10-days-of-data-engineering-interview-qna-day-5-db1c0b58bf86
NEW QUESTION # 74
You have an Azure Databricks workspace that is enabled for Unity Catalog.
You have a Lakeflow Spark Declarative Pipelines (SDP) pipeline that writes numerical data to a table named Table1 by using a data quality validation rule named rule1.
You need to modify rule1 to meet the following requirements:
Ensure that amount is always greater than 0.
Prevent an update to Table1 from being committed when data that violates rule1 is detected.
Which statement should you execute?
- A. @dlt.expect_or_drop("rule1", "amount > 0")
- B. @dlt.expect_or_fail("rule1", "amount > 0")
- C. @dlt.expect_all_or_drop({"rule1": "amount > 0"})
- D. @dlt.expect("rule1", "amount > 0")
Answer: B
Explanation:
The correct answer is C - @dlt.expect_or_fail.
Lakeflow Spark Declarative Pipelines (SDP) offers three expectation decorators, each with a different violation response:
@dlt.expect - logs the violation as a metric but writes all records, including bad ones, to the table. Suitable for monitoring only.
@dlt.expect_or_drop - drops violating records and continues the pipeline. The table receives only clean rows, but the pipeline update commits successfully.
@dlt.expect_or_fail - fails the entire pipeline update when a violation is detected. The table update is never committed. This is the correct choice when data integrity is non-negotiable: 'Prevent an update to Table1 from being committed when data that violates rule1 is detected.'
@dlt.expect_all_or_drop takes a dictionary of rules and drops violating rows but still commits - it doesn't halt the pipeline.
Reference: https://learn.microsoft.com/en-us/azure/databricks/delta-live-tables/expectations
NEW QUESTION # 75
Which layer contains cleaned and conformed data in Databricks Lakehouse architecture?
- A. Raw
- B. Bronze
- C. Silver
- D. Gold
Answer: C
Explanation:
Silver layer contains cleaned, validated, and enriched data ready for analytics. Bronze stores raw ingested data. Gold contains aggregated business-level data. Raw is not part of formal medallion architecture naming.
NEW QUESTION # 76
You have a Lakeflow Spark Declarative Pipelines {SDP) pipeline in Azure Databricks. The pipeline ingests transaction data into a table named Table1.
You need to ensure that in the event of an invalid record, the pipeline continues to run. The solution must meet the following requirements:
* Invalid records must NOT be written to Table 1.
* Invalid records must be preserved for review.
* Minimize development effort
What should you do?
- A. Add a check constraint to Table1
- B. Implement advanced logic to quarantine the invalid records.
- C. Run were clauses in downstream queries to filter out invalid records.
- D. Define a pipeline expectation.
Answer: D
Explanation:
The correct answer is B - define a pipeline expectation.
SDP expectations with @dlt.expect_or_drop are built precisely for this scenario: the pipeline keeps running, bad records are excluded from Table1, and those records are automatically captured in the pipeline's event log as expectation violations - available for review without any extra code.
Option A (custom quarantine logic) would work but requires writing and maintaining additional pipeline tables and routing logic. The whole point of SDP expectations is to handle this pattern declaratively, with far less code.
Option C (WHERE clauses in downstream queries) is a read-time filter, not a write-time guard. Invalid records would still land in Table1 and would simply be hidden from downstream views - they're not preserved for review in any structured way. Option D (check constraint on Table1) would throw an exception on write and halt the pipeline, violating the 'pipeline continues to run' requirement.
Reference: https://learn.microsoft.com/en-us/azure/databricks/delta-live-tables/expectations
NEW QUESTION # 77
......
BraindumpStudy Implementing Data Engineering Solutions Using Azure Databricks (DP-750) exam dumps save your study and preparation time. Our experts have added hundreds of Implementing Data Engineering Solutions Using Azure Databricks (DP-750) questions similar to the real exam. You can prepare for the Implementing Data Engineering Solutions Using Azure Databricks (DP-750) exam dumps during your job. You don't need to visit the market or any store because BraindumpStudy Microsoft DP-750 exam questions are easily accessible from the website.
DP-750 Pass4sure Dumps Pdf: https://www.braindumpstudy.com/DP-750_braindumps.html
Microsoft Valid Test DP-750 Test Consequently, with the help of our study materials, you can be confident that you will pass the exam and get the related certification as easy as rolling off a log, Microsoft Valid Test DP-750 Test So it's a question about how to manage our time well and live a high quality life, Microsoft Valid Test DP-750 Test Please pay close attention to you mail boxes.
Right now, even as Western economies struggle, Asia Valid Test DP-750 Test is experiencing an unprecedented war for talent, Bruiser Cruiser: Give Him a Big Hand, Consequently, with the help of our study materials, you can be DP-750 confident that you will pass the exam and get the related certification as easy as rolling off a log.
100% Pass Quiz Microsoft - Valid DP-750 - Valid Test Implementing Data Engineering Solutions Using Azure Databricks Test
So it's a question about how to manage our time well and live a Valid Test DP-750 Test high quality life, Please pay close attention to you mail boxes, Would you like to have more opportunities to get promoted?
You can easily judge whether you can pass Implementing Data Engineering Solutions Using Azure Databricks (DP-750) on the first attempt or not, and if you don't, you can use this software to strengthen your preparation.
- The best of Microsoft certification DP-750 exam training methods ???? Open ▶ www.prepawayexam.com ◀ enter ⏩ DP-750 ⏪ and obtain a free download ????DP-750 Dumps Torrent
- DP-750 Latest Study Materials ???? DP-750 Valid Exam Forum ???? Valid DP-750 Exam Bootcamp ???? ⏩ www.pdfvce.com ⏪ is best website to obtain [ DP-750 ] for free download ????DP-750 Reliable Exam Pdf
- Latest DP-750 Test Objectives ???? DP-750 Latest Test Testking ???? DP-750 Practice Online ↪ Simply search for ☀ DP-750 ️☀️ for free download on 「 www.vce4dumps.com 」 ????DP-750 Dumps Torrent
- DP-750 Reliable Exam Pdf ???? Valid DP-750 Exam Bootcamp ???? DP-750 Reliable Exam Pdf ???? Enter { www.pdfvce.com } and search for ⇛ DP-750 ⇚ to download for free ????Vce DP-750 Download
- Quiz 2026 Microsoft DP-750: Implementing Data Engineering Solutions Using Azure Databricks – The Best Valid Test Test ???? Search for ▶ DP-750 ◀ and download it for free immediately on ▷ www.prepawayexam.com ◁ ????DP-750 Test Questions Vce
- DP-750 Practice Online ‼ Test DP-750 Free ???? DP-750 Latest Test Testking ???? Download [ DP-750 ] for free by simply searching on ➤ www.pdfvce.com ⮘ ????DP-750 Dumps Torrent
- Latest DP-750 Test Format ???? Latest DP-750 Test Objectives ???? DP-750 Valid Exam Forum ???? Enter 《 www.verifieddumps.com 》 and search for ⏩ DP-750 ⏪ to download for free ????DP-750 Dumps Torrent
- The best of Microsoft certification DP-750 exam training methods ???? Copy URL ➤ www.pdfvce.com ⮘ open and search for { DP-750 } to download for free ????Exam DP-750 Bible
- The best of Microsoft certification DP-750 exam training methods ⏫ [ www.prepawaypdf.com ] is best website to obtain ➡ DP-750 ️⬅️ for free download ????Reliable DP-750 Learning Materials
- Microsoft DP-750 Questions - Latest DP-750 Dumps [2026] ???? Search on ➤ www.pdfvce.com ⮘ for [ DP-750 ] to obtain exam materials for free download ????DP-750 Latest Dumps Ppt
- 2026 Microsoft Realistic Valid Test DP-750 Test Pass Guaranteed ???? Easily obtain free download of ⮆ DP-750 ⮄ by searching on ( www.prepawayete.com ) ????DP-750 Valid Exam Forum
- allyourbookmarks.com, dianeeyvw333631.ziblogs.com, binksites.com, sirketlist.com, bookmarksusa.com, jonaspjcn219494.blog2news.com, exactlybookmarks.com, mysocialport.com, ronaldueuo944080.goabroadblog.com, gerardrdzd631878.wikimillions.com, Disposable vapes